[Home] [Resume] [Work Responsibilities] [Search Page] [IT Menu]

A redundant array of inexpensive disks (RAID) uses multiple fixed-disk drives, high-speed disk controllers, and special software drivers to increase the safety of your data and to improve the performance of your fixed-disk subsystem. All commercial RAID subsystems use the Small Computer System Interface (SCSI, pronounced "scuzzy, which now is undergoing a transition from high-speed SCSI-2 to ultra-fast SCSI-3 (also called ultra-wide SCSI). Virtually all network servers now use narrow (8-bit) or wide (16-bit) SCSI-2 drives and controllers. Ultra-wide SCSI host adapters for the PCI bus can deliver up to 40M per second (40M/s) of data to and from the PC's RAM.
RAID protects your data by spreading it over multiple disk drives and then calculating and storing parity information. This redundancy allows any one drive to fail without causing the array itself to lose any data. A failed drive can be replaced and its contents reconstructed from the information on the remaining drives in the array.
RAID increases disk subsystem performance by distributing read tasks over several drives, allowing the same data to be retrieved from different locations, depending on which location happens to be closest to the read head(s) at the instant the data is requested.
There are different levels of RAID, each of which is optimized for various types of data handling and storage requirements. RAID can be implemented in hardware or as add-on software. Modern network operating systems, such as Windows NT Server, provide native support for one or more RAID levels.
The various component parts of RAID technology were originally developed for mainframes and minicomputers. Until recently, the deployment of RAID systems was limited by its high cost to those environments. In the past few years, however, RAID has become widely available in the PC LAN environment. The cost of disk drives has plummeted. Hardware RAID controllers have become, if not mass-market items, at least reasonably priced. The cost objections to implement RAID systems are now disappearing. Your server deserves to have a RAID system; don't even consider building a server that doesn't use RAID.
RAID 5
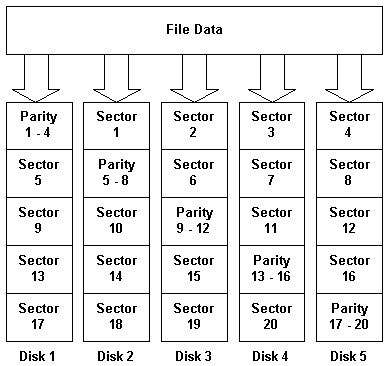
RAID 5, shown in figure 7.4, is the most common RAID level used in PC LAN environments. RAID 5 stripes both user and parity data across all the drives in the array, consuming the equivalent of one drive for parity information.
A diagram of RAID 5 (sector striping with distributed parity) with five drives.
With RAID 5, all drives are of the same size, and one drive is unavailable to the operating system. For example, in a RAID 5 array with three 1G drives, the equivalent of one of those drives is used for parity, leaving 2G visible to the operating system. Adding a fourth 1G drive to the array, the equivalent of one drive is still used for parity, leaving 3G visible to the operating system.
RAID 5 is optimized for transaction processing activity, in which users frequently read and write relatively small amounts of data. It's the best RAID level for nearly any PC LAN environment, and is particularly well-suited for database servers.
The single most important weakness of RAID levels 2 through 4 is that they dedicate a single physical disk drive to parity information. Reads don't require accessing the parity drive, so they aren't degraded. This parity drive must be accessed for each write to the array, however, so RAID levels 2 through 4 don't allow parallel writes. RAID 5 eliminates this bottleneck by striping the parity data onto all physical drives in the array, thereby allowing both parallel reads and writes.
RAID 5 Read Performance.
RAID 5 reads, like RAID levels 2 through 4 reads, don't require access to parity information unless one or more of the data stripes is unreadable. Because both data and parity stripes are optimized for sequential read performance where the block size of the requested data is a multiple of the stripe width, RAID 5 offers random read performance similar to that of RAID 3. Because RAID 5 allows parallel reads (unlike RAID 3), RAID 5 offers substantially better performance on random reads.
RAID 5 matches or exceeds RAID 0 performance on sequential reads because RAID 5 stripes the data across one more physical drive than does RAID 0. RAID 5 performance on random reads at least equals RAID 0, and it's usually somewhat better.
RAID 5 Write Performance.
RAID 5 writes are more problematic. A RAID 0 single-block write involves only one access to one physical disk to complete the write. With RAID 5, the situation is considerably more complex. In the simplest case, two reads are required-one for the existing data block and the other for the existing parity block. Parity is recalculated for the stripe set based on these reads and the contents of the pending write. Two writes are then required-one for the data block itself and one for the revised parity block. Completing a single write, therefore, requires a minimum of four disk operations, compared with the single operation required by RAID 0.
The situation worsens when you consider what must be done to maintain data integrity. The modified data block is written to disk before the modified parity block. If a system failure occurs, the data block may be written successfully to disk, but the newly calculated parity block may be lost. This leaves new data with old parity and thereby corrupts the disk. Such a situation must be avoided at all costs.
Transaction Processing with RAID 5.
RAID 5 addresses the problem of keeping data blocks and parity blocks synchronized by borrowing a concept from database transaction processing. Transaction processing is so named because it treats multiple component parts of a related whole as a single transaction. Either the whole transaction completes successfully, or none of it does.
For example, when you transfer money from your checking account to your savings account, your savings account is increased by the amount of the transfer and, at the same time, your checking account is reduced by the same amount. This transaction obviously involves updates to at least two separate records, and possibly more. It wouldn't do at all to have one of these record updates succeed and the other fail. On the one hand, you'd be very upset if your checking account was decreased without a corresponding increase in your savings account. Similarly, the bank wouldn't like it much if your savings account was increased but your checking account stayed the same.
The way around this problem is a process called two-phase commit. Rather than simply write the altered records individually, a two-phase commit first creates a snapshot image of the entire transaction and stores it. It then updates the affected records and verifies that all components of the transaction completed successfully. After this is verified, the snapshot image is deleted. If the transaction fails, the snapshot image can be used to roll back the status of the records that had already been updated, leaving the system in an unmodified and coherent state.
RAID 5 uses a two-phase commit process to ensure data integrity, further increasing write overhead. It first does a parallel read of every data block belonging to the affected stripe set, calculating a new parity block based on this read and the contents of the new data block to be written. The changed data and newly calculated parity information are written to a log area, along with pointers to the correct locations. After the log information is written successfully, the changed data and parity information are written in parallel to the stripe set. When the RAID controller verifies that the entire transaction completed successfully, it deletes the log information.